读者:互联网观察人员、互联网媒体及广告从业人员、互联网开发技术人员、网络黑客
关键字:用户跟踪(User Track)、Cookies、URL、Google、广告
引言:随着Firefox大举蚕食微软IE的浏览器市场,新一轮的桌面浏览器大战序幕已被拉开。无论是微软、Mozilla、Google 、Opera,还是许多其他非主流浏览器生产厂商,都盯着这块蛋糕,以及蛋糕后面不可估量的市场——互联网定向广告。
首先我们和以往一样,要定义什么是这里关注的“ 用户信息”。 这篇文章中,及我本人理解,用户信息是能够标识唯一用户(UUID: Universal User ID)的信息。但从个人来讲,这其中亦或包括姓名、性别、年龄、种族、居住地、籍贯等个人信息,不过我们所要说的,应该是更关注能代表其“Life Style”的信息,比如工作、工种、收入、喜好、在互联网上的行为等,这种信息也许无法完全标准化,但是可以通过了解这个人的兴趣爱好,进而判断他的“ 属性”,以便获取到对商业公司有利的信息。从群体来讲,亦或包含他的朋友、圈子、获取信息来源等等。所以, 这里所谓的用户信息,是指用户是谁、他在网站上干了什么的“绑定用户身份的用户行为数据”。
目前有哪些手段可以获得活动在互联网上的用户信息呢?
首先,CPU级。 Intel和AMD是可以的,因为CPU处理所有电脑上的数据,而所有数据对CPU来说都是透明的,如果这两位想获得用户数据,从CPU下 手是不二选择。不过这不太可能:一是因为Intel和AMD不能获取使用对方CPU的用户数据——两家的CPU不兼容;二是因为这有悖用户隐私,用户肯定 不会为增加而外的对自己没有好处的CPU运算量而买单,要知道CPU的所有运算最终都是由主机供电来维持的,用户除了要为CPU的额外功能买单,更要为以 后消耗的电费买单,用户肯定不答应;三是两家不可能形成战略合作平台,推动一个跟自己本身业务没什么联系的服务。
其次,操作系统级。 这方面微软首当其冲,借助Windows系列强大的装机量在底层获取用户信息并发送到互联网上。不过这也没什么可能:微软虽然知道这块蛋 糕又大又诱人,但是个人隐私在美国绝对是碰不得的,微软面临过太多类似的问题和诱惑,应该不会从操作系统着手获取普通用户的隐私。再看类Unix系统,这 是由黑客领导、社区贡献开发出来的系统,他们不会买广告主或媒体的帐,对于这种对用户没有好处的事情,他们只会反对。如果不是底层开发,光靠某些人某些团队无法形成大规模下载和使用,没有商业价值。
第三,客户端。 像艾瑞的iClick这种专门为搜集用户信息的软件就是此类,很多国外赚钱网 站也都有这种既显示广告又搜集信息的软件。这种软件可以获取客户端的所有信息,包括本地信息和互联网活动情况,理论上可以跟踪每一个装上此类软件的用户, 确定用户唯一身份,并跟踪其每个行为,进而知晓用户的Life Style。但这类软件局限性大,如果想知道一般用户的信息,靠这种专业软件肯定不行。用户如果不是有利益驱动不会单独安装此类软件。所以,QQ、MSN 或者迅雷这类知名度高装机量大的软件才有机会成为搜集用户信息的工具。
第四,浏览器。 浏览器即是客户端,同时也是普通用户和互联网接触的主要工具,其地位的特殊性决定了它是获取用户信息的最佳和可靠手段。不过无论是IE、Firefox还是Opera都不会这么做,一是三家各占江山一部分,互相之间不兼容;二是隐私保护。
第五就是基于浏览器的第三方插件了。 随着IE8的临近,这种插件的方式几乎是浏览器必备的工作模式。而从普遍用户接受插件开始,就有无数插件觊觎这些用户访 问数据。插件通过浏览器执行,有足够的权限获取本地信息和基于本浏览器的互联网用户活动信息,但是这类插件如果不能解决装机量的问题,无法成为主流,而且同样面临法律风险。
其实上面那些都是废话,主要是回顾下历史,同时给新来的同学扫盲。
下面具体说下:
互联网时代可行的用户信息搜集跟踪软件
首先 这类软件应该具备以下特征:
1. 能够跟踪确定唯一用户,否则达不到我们命题中的要求;
2. 用户信息是在用户知晓和允许的情况下被发送的,否则会面临法律风险;
3. 这种软件与平台无关与浏览器无关,否则样本采样就受到平台和浏览器的限制;
4. 这种软件装机量足够大,不然就没有统计意义。
那么 这类软件将面临什么问题和如何解决呢:
1. 避免被网络防护设备和软件过滤和杀掉,比如防火墙、杀毒软件、系统维护软件等;
2. 不经用户允许,不能发送信息,但如果一旦发送,必须保证发送的数据是完整和未经筛选的;
3. 应该对用户有用,不然用户不会帮助你搜集他们个人的信息和行为数据。
我看好的这样的客户端软件是flash、java虚拟机(JVM)和Google工具栏,而又是Google工具栏最被看好。因为做Flash的Adobe和做JAVA的Sun都是做开发和实现的,不是做媒体和广告的,只有Google即做开发又做媒体、即关注技术又关注广告的。

我们讨论一个相关的,但是额外的话题:
哪些信息能够准确定位唯一用户?
首先操作系统的用户名是一个不错的选择,不过光靠用户名无法确认唯一用户,因为比如像Administrator、Guest、root这种角色用户在所 有电脑上默认情况下都是这个名字,而对终端用户来说他们不会特意修改这些名字——只要能用就好。所以单靠用户名是不行的。与此情况类似地,靠域+用户名, 或者工作组+用户名的方式同样不能满足我们的要求。
那么进一步地,Mac ID+用户名怎么样?Mac ID可以认为是全球唯一,这串16^12的字符可以容纳百兆级的网卡和网络设备互相联通而不冲突,虽然有的虚拟机会将自己生成的虚拟网卡设定同一个Mac ID,不过由于使用虚拟机的人是少数,不影响整个统计数字的可参考性。而且随着虚拟机软件的发展升级,这个问题完全可以解决。我个人认为,典型情况下, Mac ID+用户名的方式可以确认唯一用户。
类似的还有其他方法,不过这些方式还是有局限性,就是程序必须要读取本地信息的权限。这对于网站开发者,尤其是Web 2.0簇拥者们来说是不可饶恕的。除非用户允许,否则仅从服务器端代码程序是无法获取这些信息的,而一般情况下,用户肯定不会允许这种跟踪程序或者嗅探狗进入自己的电脑。所以只有提供用户认可的服务,同时监控这些数据的软件才有机会合理合法地获取到这些数据。从这点上看现在流行的浏览器工具条都有这样的权 限和功能,不过还是Google的工具条做得更到位——在用户欲开启Page Rank时提示用户他们的信息会被发送会服务器,而不是在安装时放到没人看的安装声明中。
Google工具条也有足够的装机量和知名度,不会被杀毒软件或防护软件判刑。而依附于浏览器执行的Google工具条可以通过浏览器一定程度上规避防火墙的追踪,成为合法程序。
Google通过Google工具栏,可以获取用户硬件信息,通过Google帐号,可以将帐号和硬件信息绑定,从而确定唯一用户。
从目前的Google工具栏来看,它可以判定用户访问了那些网站,记录用户标注为“Favorite”的网站,甚至可以记录用户访问过网站其中交互的数据。 这从技术上来讲不是什么难事,不过由于每个网站自己设计的不同,在实现上可能会需要一个很大的数据库记录每个网站用户每次点击对应的交互信息,这或许也是 云计算要解决的问题。
这些,Google工具栏都能很好地一一规避,并且也很好地处理了用户隐私,不存在法律风险,而且,Google有能力处理和分析这些数据,Google一贯的“不作恶”深入人心。
但是光凭Google工具栏,并不能包含所有的样本,Google工具栏并不能涵盖所有上网用户,那么如何搜集那些没装Google工具栏的用户信息 呢?Google Analytics提出了一种解决方法。具体技术原理不再详述,不过随着NoScript和其他这类Firefox插件的兴起,Google Analytics的统计代码陷入一个黑洞。诚然,NoScript是一个也许高级用户才会修改配置的插件,不过其默认设置是禁止第三方网站js脚本执行 的,也就是默认情况下,除了Google本站的Analytics统计代码,它默认是禁用所有第三方网站调用执行Google Analytics代码的,同样还有Yahoo、51la等统计网站的统计代码。虽然目前使用NoScript的用户还没形成对整体样本库的压力,不过至 少Google Analytics流失了很多高质量用户的行为数据。这个问题是Google和广大站长需要解决的。
另外一个问题:
不靠客户端程序,如何识别用户信息?
基于Cookies认证的方法也许是一个可行的办法,不过Cookies天生就不是为了储存用户行为而设立的东西,它只不过是为了方便服务器识别每个用户及其使用习惯在客户端写入的极小的文本文件。而也许不方便跟踪用户的行为,而上面提到过,如果Analytics统计代码无法使用的情况下,服务器和站长如何获取用户个人信息和其行为数据的绑定?
我想到的一个也许可行的方法是 Cookies确定个人信息,通过HTTP信道加密,在URL生成唯一特定UID的方法,确认每个用户的行为。
这方面QQ是个很好的例子,当你的好友在QQ空间发表了一篇文章,你的对应QQ好友头像旁边会有一个五角星提示,当你点击这个五角星打开浏览器窗口时,会生成一个很长的网址:
zzpanelkey=64_bit_long_coded_number&zzpaneluin=my_qq_number&url=htth%3A%2F%2Fuser.qzone.qq.com%2Fmy_friend_qq_number
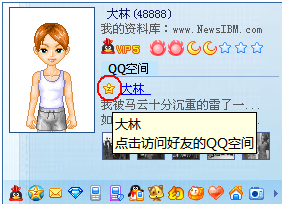
这里zzpanelkey其实就是一串可以标识特定用户的加密字符,只不过QQ没有使用https协议,无法保证数据在传输过程中的隐密性,不过其思路是可 以借鉴的。另外,如果这个zzpanelkey有包含标识用户个人数据的原始信息在里面,即使被嗅探也无法还原。所以可以认为是可行的解决方法,不过其局限性在于如果没有统一规定,各个网站之间的数据无法通用,而且URL长度也有限制的。
总结:本文浅析了流行的追踪用户信息的手段极其不足,给出了作者认为可行的解决方法,并引申出了相关问题,期待未来被解决。
当然,最后,我们忘了另一个活跃于网络领域的——网络设备,所有数据都是通过它们传送的,当然它们就可以监听到所有的网络数据。虽然它们无法获取特定用户的 信息,不过,它们还是可以通过跟踪Mac地址及用户接入网段以及用户传递的数据来了解一个人,进而知道这个人的Life Style。和电话窃听类似地,通过嗅探的方式可以任意定位用户位置和通信内容,即使你知道他们这么做你也无法解决这个问题。每个国家的保密部门都会窃听 电话,你还不是每天都打电话?在这个领域,思科和华为是最有竞争力的两个厂商,不过同样地,他们也得首先解决隐私问题。因为他们是商业公司,而不是情报机构。
网络计算机防护的主要手段
在实际应用中,除了这些可以满足我们需求的获取用户信息的软件,还有一些防护软件,这些软件一般都会控制我们读取用户权限的可能,最大限度地减少我们获取 到的用户信息。这并不是说我们的获取就违反了安全措施,只是由于安全软件的策略,发送用户数据的程序一般都会被认为是“黑名单”程序。
而从目前的防护手段上来看,主要分三层防护:一是网关防护,一般是指路由器交换机这种又网络设备能控制的防护;二是终端防护,主要是指每台电脑由防火墙控 制的网卡防护;三是软件防护,这种防护五花八门,比如组策略、修改hosts文件等等,方法太多不一一列举。当然,这里我分的比较粗,其实但从 TCP/IP协议来讲就有7层,每层都有方法可以防护,但是很多防护方法并不常见,也不适合终端用户,所以就不深入讨论了。
网关防护 主要能做到对域名和IP的判断防护,对符合条件的信息做黑名单或者白名单处理,这种方法实施起来比较简单,但是功能也有限,而且并不是所有的网络设备都有这些功能。
终端防护 是目前最常见的方法,在操作系统上安装个杀毒软件+防火墙,或者仅仅是用Windows自带的防火墙+安全卫士360这些软件,就可以满足日常需 要了。这些软件主要是通过扫描注册表特定键值、浏览器特定CLSID、特定域名、内存中特定字符串的方式,和自己的“病毒库”进行对照,从而查杀有害程序 和插件。
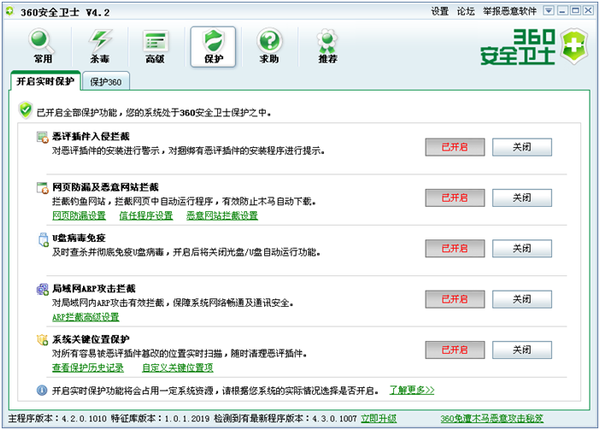
软件防护 简单说来就是利用360安全卫士,或者超级兔子、Windows优化大师这类的软件辅助用户进行主动防护。曾经有一款小软件叫upiea,可以扫描IE浏览器几乎所有的插件程序,并进行主动防护,对高级用户其实是很有效的。
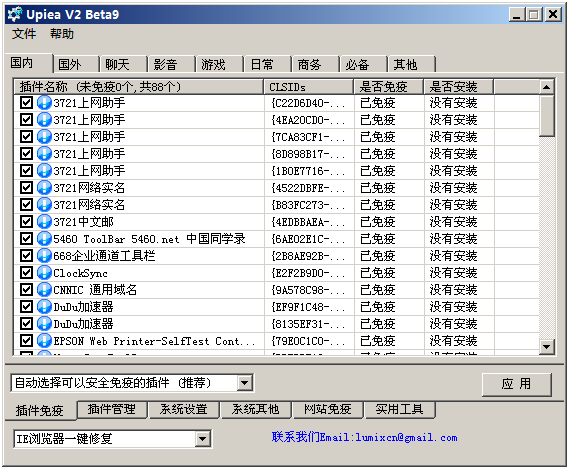
不过对一般用户来说,可能稍微专业了点。其实它就是判定浏览器插件的CLSID,并和自己数据库的信息进行比对匹配,进而进行各种操作。另外它还可以修改 hosts信息,并且本身储存了许多实用的广告网址,将这些网址直接指向255.255.255.255,不但节省了互联网流量,也清洁了用户浏览的界面。